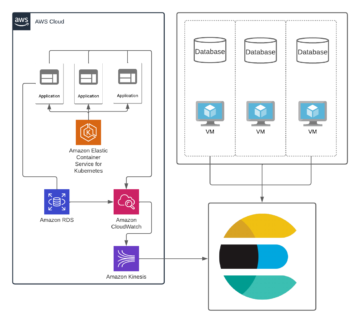
Solita Cloud Academy: a Fast Track to Cloud Business
It’s not a secret that the competition for talent in the tech industry is tough and particularly challenging among cloud professionals. According to forecasts, the cloud market will multiply in the coming years. Nordic countries are leading the way in cloud adoption, and to keep the development going, there is a huge need for skilled people.
To meet the needs in the market, Solita came up with a solution: a carefully tailored training path for IT professionals who desire to become Cloud experts.
“The talent shortage is a real issue, so we decided to train people ourselves. We want to continue growing our cloud business and serve our customers with their digital transformations also in the future”, says Karri Lehtinen, SVP of Solita Cloud Platforms.
Solita Cloud Academy educates new public cloud specialists to work on Solita projects. Right now, the main focus will be on Microsoft Azure training and Solita Cloud Platforms Way of Working, including mastery of Solita CloudBlox.
Cloud Academy will be started several times during 2023, and two to four students will be recruited for each round. Academians will get 12 months membership in the Sovelto PRO program and will accomplish the Azure Solution Architect Path during the first three months. The program is designed together with Sovelto Eduhouse.
“The benefit of this concept is that people can join customer projects quickly after three months of training. We want to keep the groups small to ensure sufficient support and a clear track to customer projects”, says Saila Karonen, the Talent Acquisition Owner in the Cloud Community at Solita.
The demand for Azure know-how is very high right now, which explains the chosen technology. But it is very possible that some of the future academies will focus on other technologies. Each Academy is tailored based on the prevailing needs in the market.
Solita Cloud Academy is for people who already have experience in the IT industry
This Academy is specifically targeted at people with experience in the IT industry who are now willing to learn how to design and implement public cloud infrastructures with infra-as-code. The ideal candidates have worked on IT projects before and share Solita’s philosophy
about automation coming first.
“We’d like to see cloud-curious people who know the industry and understand tech. They could be, for example, software developers or system specialists who have at least a basic understanding of IT Infrastructure Platforms”, says Lauri Siljander, the Principal of Cloud Academy.
On top of technology training, students will go through full onboarding to Solita. They will be employed by Solita from day one and receive fair compensation during these three months of studying. After graduation, there will be a salary review and discussion.
A career path to Solita’s Cloud Community
The first group of Solita Cloud Academy students is in their second month, and the experience so far has been positive. Students have felt that it’s a good combination of guided and autonomous studying, with both peer and tutorial support at hand. People are participating from different parts of Finland, so the program is fully virtual and currently conducted in Finnish.
Solita Cloud Academy is a path to Solita’s Cloud Community, a unit of about 100 Cloud Professionals in Finland. The community is passionate about quality and cares for customers’ business results. It’s a workplace where people are encouraged to craft their own path based on their interests while being open to learning and sharing their knowledge with others.
Joining Solita Cloud Community means being part of a value-driven culture where people help each other and want to make a long-lasting impact – together.






























 In the reception there was artists to draw picture of you.
In the reception there was artists to draw picture of you.