Alerting Estonian Citizens with Azure
The author of the article works for the company Solita as a Data Engineer since 2019 and specialises in cloud-based data platforms. By now, he has accumulated more than 20 years of experience in various fields of the IT sphere – development, architecture, training. Many interesting projects have been made both in Estonia and abroad.
The beginning
In the digital state’s Hackathon event, Solita addressed the transmission of government’s cultural messages to televisions via an Android app.
In parallel, the Ministry of the Interior’s IT Centre (SMIT) pointed out a similar need. Sending alarm messages from the SITREP (Situation Reporting) system to the mobile application ‘Ole valmis!’ (‘Be ready!’) was considered. The purpose of that application became to warn the user of a nearby accident or deteriorating weather (such as a snowstorm, or a coastal flood).
In conclusion, since the pattern was the same, it seemed reasonable to create a single, unified solution.
Problems and objectives
SITREP did not have a public interface for requesting messages, but it did have the functionality to send messages. So it was possible to interface the system directly with the back-end of the ‘Ole valmis!’ (‘Be ready!’) application. The following goals emerged in the process of the Hackathon, which led to the development of a separate cloud-based system.
- Transmission of messages (push and pull) must be possible to several channels in parallel, whoever the consumer is.
- The messaging functionality must be separate from SITREP.
- The interface must be secure so that a malicious actor cannot send false alarms.
- It must be easy to administer.
- It must be possible to subscribe / categorise messages by subject and location.
- Setting up the system must be quick and easy.
- The system must be flexible and inexpensive to maintain.
- The available development time is a couple of man-months.
Why Microsoft Azure?
Solita participated in the Hackathon in partnership with Microsoft, which is why Azure was chosen as the cloud environment – although similar solutions could be created with the help of AWS or Google, for example. Azure also provides some direct benefits.
- Most components can be easily integrated with Active Directory (although Active Directory was not an end in itself in the first iteration, this was one argument to consider in the future).
- The range of services (in other words – the arsenal of ‘building blocks’ of the completed system) is really impressive and also includes exclusive components – in the following we will take a closer look at some of them.
For example, API Management is, to put it simply, a scalable API gateway service, and as a big bonus, it includes a public Web portal (Developer Portal) that is convenient for both the user and the administrator. In addition, the interface can be redesigned to suit your needs. The main value comes precisely from the ease of use – you don’t have to have much Azure-specific knowledge to sign up, send / receive messages, set the final destination, describe conversion rules.
The Developer Portal provides developers with pre-written sample code for consuming messages (presented in cURL, C#, and Python, for example). In addition, of course, a built-in firewall, resilience, and resistance to DDoS-type attacks are provided. All of the above saves a lot of time (and money!) from the user’s, administrator’s and developer’s point of view.
Infrastructure creation process
From the architect’s point of view, the aim was to create a system based on the most standard possible components (provided by Azure itself), and the installation of which would be simple enough for anyone with a basic knowledge of the working principle of the cloud. Account had also to be taken of the fact that the requirements were also still evolving.
From the beginning, we relied on the principle of IaC (Infrastructure as Code) – the entire infrastructure of the solution in the cloud is unambiguously described as human and machine readable code. In addition, the installation process would be incremental (if a new version is created, the existing infrastructure could be updated instead of recreating), configurable and automated; the code would be as clear and editable as possible. Figuratively speaking, you press ‘deploy’ and you don’t need much else.
All of the above is made possible by a tool called Terraform, which is quite common, especially among those who administer infrastructures – so-to-speak the de-facto standard for precisely cloud infrastructures. It is a free tool produced by HashiCorp that is perfect for situations like this – a person describes in a code what resources he needs, and Terraform interprets the code into instructions that can be understood by the (cloud) environment to create, modify or delete them.
Terraform has the following strengths that were the decisive factor:
- its spread and wide platform support,
- the ability to ‘remember’ the state of the installed infrastructure,
- the simple but powerful HCL language that can be used to describe even complex logic.
The method officially supported by Microsoft for achieving the same are ARM templates (ARM templates are essentially structured static JSON or YAML). The entire Azure infrastructure can be described based on purely ARM templates, but then more code is created and the possibilities of directing the installation logic are greatly reduced.
Changing requirements and options
The first thing that the work continued on was creating a message store (for pull scenario and debugging).
The initial understanding of the message format was quite simple:
- single-level JSON,
- a few required attributes (timestamp, author, etc.),
- rest of the schema was completely open.
Based on the above and on the principled decision to use only Microsoft Azure components + to install the entire solution with a single command, two options remained on the table for storing and reading JSON data without a defined schema:
- Table Storage (default; although by operating principle it is a key / attribute type service),
- Cosmos DB.
The ability to query data via HTTP(S) (less development work) and a lower cost (especially important in the prototype phase) spoke in favour of Table Storage; Cosmos DB had the advantage of storage flexibility, as it stores data in several regions. However, the situation was changed by the fact that SITREP’s messages came as a multi-level JSON and some of the critical attributes were at a ‘deeper’ level. Therefore, Table Storage no longer met the new requirement and the Cosmos DB component had to be introduced instead.
In addition, there was a real possibility that the system would be used in a context other than alarm messages – it had to be taken into account that the system could be used for transmitting virtually any message from many senders to different channels in different combinations. In essence, the goal became to create a messaging platform (Message Service Provider) that would functionally resemble the products of Twilio or MessageBird, for example.
Not a single line of ‘real’ code
So, by now, the following was architecturally in place:
- all incoming messages and queries went through API Management,
- all messages were stored in the Cosmos DB database.
At the same time, pushing messages to destinations through API Management remained an open issue. And exactly which component handles the database of messages and destination addresses?
Microsoft Azure offers options for almost any scenario, from an application hosted on a virtual machine to a serverless component called Azure Function. You can also use a number of intermediate variants (Docker, Kubernetes, Web App), where the user may or may not have direct access to the server hosting the application.
In the context of the present solution, all the above solutions would have meant the following:
- a person with a developer background would have been needed to create the system,
- the system as a whole could no longer be installed very easily – the application code would have been separate from the infrastructure code.
Fortunately, Azure has provided the Logic App technology that addresses the above issues. It’s a way to describe business logic as a flowchart – for example, you can visually ‘draw’ a ready-made Logic App ‘application’ in the Azure Portal, using the online interface.
It is true that in more complex cases, such as conversion operations, you will probably need to write a few lines of code, but this is far from traditional programming. Writing Logic App code is more akin to developing Excel macros than Python or Java.
The Logic App flow code can be saved as an ARM template, and the ARM template can be used as part of a Terraform installation script – making the Logic App a great fit for this context. Starting a single workflow in this solution costs in the order of 0.0005 euros per occasion (according to the consumption-based plan) – yes, there are even cheaper solutions like Azure Function, but in this case the infrastructure needs to be installed and developed separately.
Support components
Azure has well-thought-out tools for monitoring the operation of the system; in this case we focus on two of them: Azure Monitor and Log Analytics. The first, as the name suggests, is a set of dashboards provided by the Azure platform that help monitor the status of applications and components (including in real-time), such as load, memory usage, and user-defined metrics.
Since the Monitor is ‘included’ with every solution by default, it may not be correct to consider it as a separate component – it is simply a question of displayed indicators. Log Analytics, on the other hand, is a place to direct the logs of all components so that they can be conveniently analysed and queried later. This helps detect system errors and quickly track down errors. You can even query Log Analytics for metrics to display later in the Monitor, such as the number of errors per day.
Results and observations
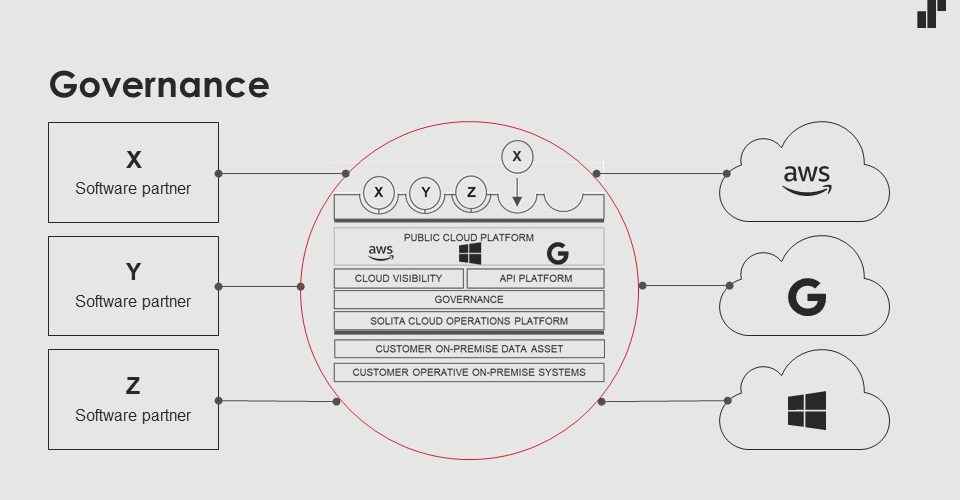
In summary, the architecture of the solution came out as follows.
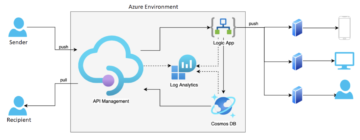
Broadly, the objectives set out at the start were achieved and the principles were followed (IaC, Azure components only, etc.). Clearly, Microsoft Azure offers a truly comprehensive suite of services with typically 99.95-99.99% SLAs; however, ‘the seven nines’ (99.99999%) or even higher are not uncommon. Such a high percentage is achieved through redundancy of components and data, optimised hardware usage, and exceptionally strict security measures in the region’s data centres.
Installing a system from scratch on an Azure account takes 45-60 minutes, and the lion’s share of this is provisioning API Management – a kind of heavyweight in Microsoft Azure, with a number of internal components hidden from the user (firewall, web server, load balancer, etc.).
There were no obstacles, but the development revealed that Terraform is a few steps behind Microsoft Azure as a third-party tool – in other words, when Microsoft launches a new Azure service, it will take time for HashiCorp developers to add functionality to their module. In this case, for example, the ARM template for the new component can be partially grafted into Terraform scripts, so that the creation of the infrastructure can be automated in any case.
In conclusion
Public cloud providers, such as Microsoft Azure, have hundreds of different services that can be considered Lego blocks – combining services to create the solution that best meets your needs.
The article describes how an MSP-like product was created from scratch that has reached the pre-live status by now. The same product can be assembled from different components – it all depends on the exact needs and on the possibilities to include other competencies, such as C# or Java developer’s. The public cloud is diverse, secure, affordable and ever evolving – there are very few reasons not to take advantage of it.
Thank you: Janek Rozov (SMIT), Timmo Tammemäe (SMIT), Märt Reose (SMIT), Kristjan Kolbre (‘Ole valmis!’), Madis Alesmaa (‘Ole valmis!’), Elisa Jakson (Women’s Voluntary Defence Organisation / ‘Ole valmis!’), Henrik Veenpere (Rescue Board).





 Name the process as “Scrum customize”
Name the process as “Scrum customize”










 Multiregion deployment needs some extra attention
Multiregion deployment needs some extra attention