

Log Format in Modern Architectures
Modern solutions can grow rather complex and can carry a lot of legacy. That’s why streamlining your logs and centralizing them is quite frankly the only option. But when we have the log data in order, it’s quite easy to transform log data into dashboards, for example to visualize data like success percentage from HTTP responses or API request rate. It’s also much easier to implement or integrate systems like SIEM into your architecture, when you already have a working centralized logging.
System Complexity
The more complex your system is, the more it can benefit from centralized logging and it’s monitoring. If it’s done well that is. A good example on when centralized logging is almost mandatory, is any type of microservice – based architecture. Microservices or microservice architecture, is an architectural style in which application is a collection smaller services. These services have specific functionalities and can be independently deployed, tested and developed. Comparing this to microservices counterpart, monolithic architecture, which is a single unit running everything, we can avoid issues like single bug breaking whole system or updating one thing requires a full deployment, risking outages. With microservices a bug is limited to a single service and functionality. Updates, like security patching, can be done to a single service without disrupting the system. Below is a diagram on how microservices can work for example in an e-commerce application.
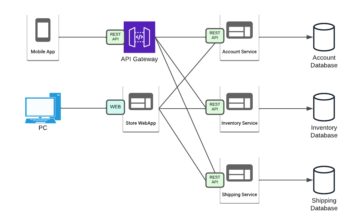
Microservices have their own downsides, like more complex deployments where instead of one service you must take care of possibly hundreds of individual services and their integrations. Orchestration tools like Kubernetes, OpenShift and Docker Swarm can help but these too bring additional complexity. It can also be a pain to troubleshoot, where a misconfiguration in one service can cause an error in another. Therefore, having applications logging with unique identifiers and events is important in more complex systems.
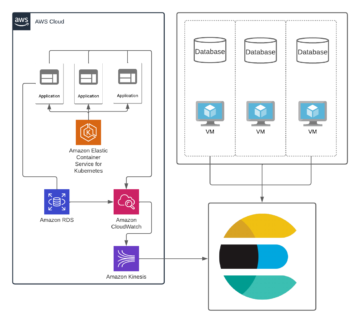
Also, a common situation is a hybrid solution, where let’s say Kubernetes, is managed by a cloud provider while databases still exist on-premises. Staying on top of what’s happening in these kinds of setups is challenging, especially when old systems can cause some legacy related issues. But all hope is not lost, by following the same rules in both the cloud and on-premises, these hybrid solutions can be tamed, at least when it comes to logging. Below is an example of an hybrid environment, where part of the solution is run on AWS and some are still on-premise. It’s quite simple to integrate all systems to centralized logging, but it becomes more important to have log format that all services will follow due to system complexity.
Another topic worth to discuss is SIEM (security information and event management). Many companies have a requirement to track and manage their security events and know what is going on in their system. Now managing SIEM isn’t an easy task, far from it. Anyone who works with it, needs to know what they want to follow, what they need to react to and how to get that information out of the system. Usually, audit logs are delivered to SIEM in a specific format, which enables SIEM to understand how important and critical each log is. If logs are formatted and implemented properly, implementing or integrating your logging to SIEM shouldn’t be an issue. But if not, delivering raw audit log can quickly raise costs in size and in the amount of work required to get it running.
Standard log format
Usually, you need to know what kind of data you want to log. While many services provide metrics out of the box for easy integrations, usually logs need more attention to be useful. Each log should follow a standard log format. Now imagine if each service would have totally different log format. Issue is not only that there would be a huge number of fields but that those fields might overlap. If a field is overlapping and the data types are different, one of the log lines will not be indexed. Format could include fields like:
- Service name
- Timestamp
- Unique identifier
- Log level
- Message
Creating your own log format makes most sense when you control logging configuration in your software. For third party software, it’s not always possible to modify their logging configuration. In this case it’s usually best to filter and mutate log data based on certain tags or fields. This can get more complex with hybrid environments, but it’s highly beneficial, when everything is following the same format, even if only partly. It can also be beneficial to have these logs in separate index, to avoid possible conflicts with fields. Using features like dynamic mapping in Elasticsearch can make our life and scaling easier in the future.
Unique Identifier
In addition to standard log format, it is useful to have a unique identifier, especially with microservices, which we will talk about later. This identifier is attached to incoming request, and it stays the same while the request moves through the system. This comes handy when troubleshooting, where the first thing is to identify the unique ID in the log. By searching for this ID, it’s possible to track requests trail from the moment it came to the system to where it failed or they did something weird. Identifier can be something like a UUID in a header of an HTTP request or something more human readable. Having standard format and unique id means that the organization or development unit needs to work with the same standard requirements and guidelines. While our typical log format example provides important information like timestamp and service name, we need more information in our message field (or in some other field). Something simple as HTTP responses are usually a good place to start and are easy to filter when looking for errors.
Log levels
Log levels are rather self-explanatory, for example most logging frameworks have the following log levels:
- ERROR
- WARN
- INFO
- DEBUG
- TRACE
If our earlier blog tried to explain anything, it should be that log levels like TRACE and DEBUG shouldn’t be logged, except when actual troubleshooting is needed. It’s good to plan your levels so, that only ERROR and WARNING are needed to notice any issues with your software and INFO shouldn’t be just renamed DEBUG log. Having some custom levels, like EVENT, can help to filter logs more efficiently and quickly describe what the log is about.
Event logs
To improve the ability to track and troubleshoot your applications, event logs are really handy. They also have high business value, if event logs are used to create event-driven architecture. Having event logs requires work (again) from the application team. It’s more difficult to modify third party applications, as maintaining those changes requires dedication. Event logs should contain information on what type of event has happened in the application. These events can be their own log level, like EVENT, or just be included in the message. In a larger system, having events tied with the unique identifier helps to keep track of users and their process through the system. Even if events aren’t their own special category, all applications should log messages that make sense to developers and people reliant on said information. Implementing event information and unique identifiers is a large task and needs to be done unitedly across the whole system. But the payoff is clear visibility to the system through logs and the ability to leverage log data for monitoring, troubleshooting and security purposes. When using log4j2 in java based applications, it’s possible to use EventLogger class, which can be used to provide a simple mechanism for logging events in your application.
Conclusion
Logging is easy when you only have one piece of software or just a small system to operate. But the higher we grow and more we stack up our stack, more difficult it gets to see everything that’s happening. That’s why we need to but our trust into more software, that can handle all the information for us. Having a proper logging is crucial in this modern day and modern architecture but not that many are able to take advantage of it. Most of the centralized log management tools can be used to visualize and create dashboards from your log data, turning the flood of logs into something useful rather easily.