My Thursday at AWS re:Invent 2019
Keynote by K Dr. Werner Vogels
Dr. Vogels is CTO at AWS. The keynote started with very detail information about virtual machine structure and evolvement during the last 20-25 years. He said that the AWS Nitro microVM is maybe the most essential component to provide secure and performance virtual machine environment. It has enabled rapid development of new instance types.

Ms. Clare Liguori (Principal Software Engineer, AWS) gave detail information about container services. In AWS there are two container platforms, the ECS EC2 with virtual machines and the serverless Fargate. If you compare scaling speed, the Fargate service can follow the needed capacity much faster and avoid under-provisioning (for performance) and over-provisioning (for cost saving). With ECS you have two scaling phases, first you need to scale up your EC2 instances and after that launch the tasks.

During the keynote Mr. Jeff Dowds (Information Technology Executive, Vanguard) told their journey to AWS from corporate data center. Vanguard is registered investment advisor company located in USA and has over 5 trillion USA dollars in assets. Mr. Dowds convinced the benefit of public cloud by hard facts: -30% savings in compute costs, -30% savings in build costs, and finally 20x deployment frequency via automations. Changing the mindset of deployment philosophy, I think is the most important change for the Vanguard. Like said in the slides, they have now the ability to innovate!

Building a pocket platform as a service with Amazon Lightsail – CMP348
Mr. Robert Zhu (Principal Technical Evangelist, AWS) kept chalk talk session about the AWS Lightsail service. He started saying that this talk will be the most anti-talk in re:Invent in meaning of scaling, high availability and so on. The crowd was laughing loud.
In chalk talk the example deployed app was a progressive web app. PWA apps try to look as a native app e.g. in different phones. PWA’s typically use web browser in the background with shared UI code between operating systems.
The Lightsail service provides public static ip addresses and simple DNS service that you can use to connect the static ip address to your user-friendly domain name. It supports wildcard records and default record which is nice. The price for outbound traffic is very affordable: in 10 USD deal you get 2TB outbound traffic.
We used a lot of time how to configure a server in traditional way via ssh prompt: installing docker, acquiring certificate from Let’s encrypt etc.
The Lightsail service has no connection to VPC, no IAM roles, and so on. It is basically only a virtual server, so it is incompatible for creating modern public cloud enterprise experience.
Selecting the right instance for your HPC workloads – CMP409
Mr. Nathan Stornetta (Senior Product Manager, AWS) kept this builder session. He is a product manager for AWS ParallelCluster. In on-premises solutions you almost always need to do choices what to run and when to run. With public cloud’s elastic capacity, you don’t have to queue for resources and not to pay what you are not using.

HPC term stands for high performance computing which basically means that your workload does not fit into one server and you need a cluster of servers with high speed networking. Within the cluster the proximity between servers is essential.
In AWS there exists more than 270+ different instance types. To select right instance type needs experience about the workload and offering. Here is nice cheat sheet for instance types:
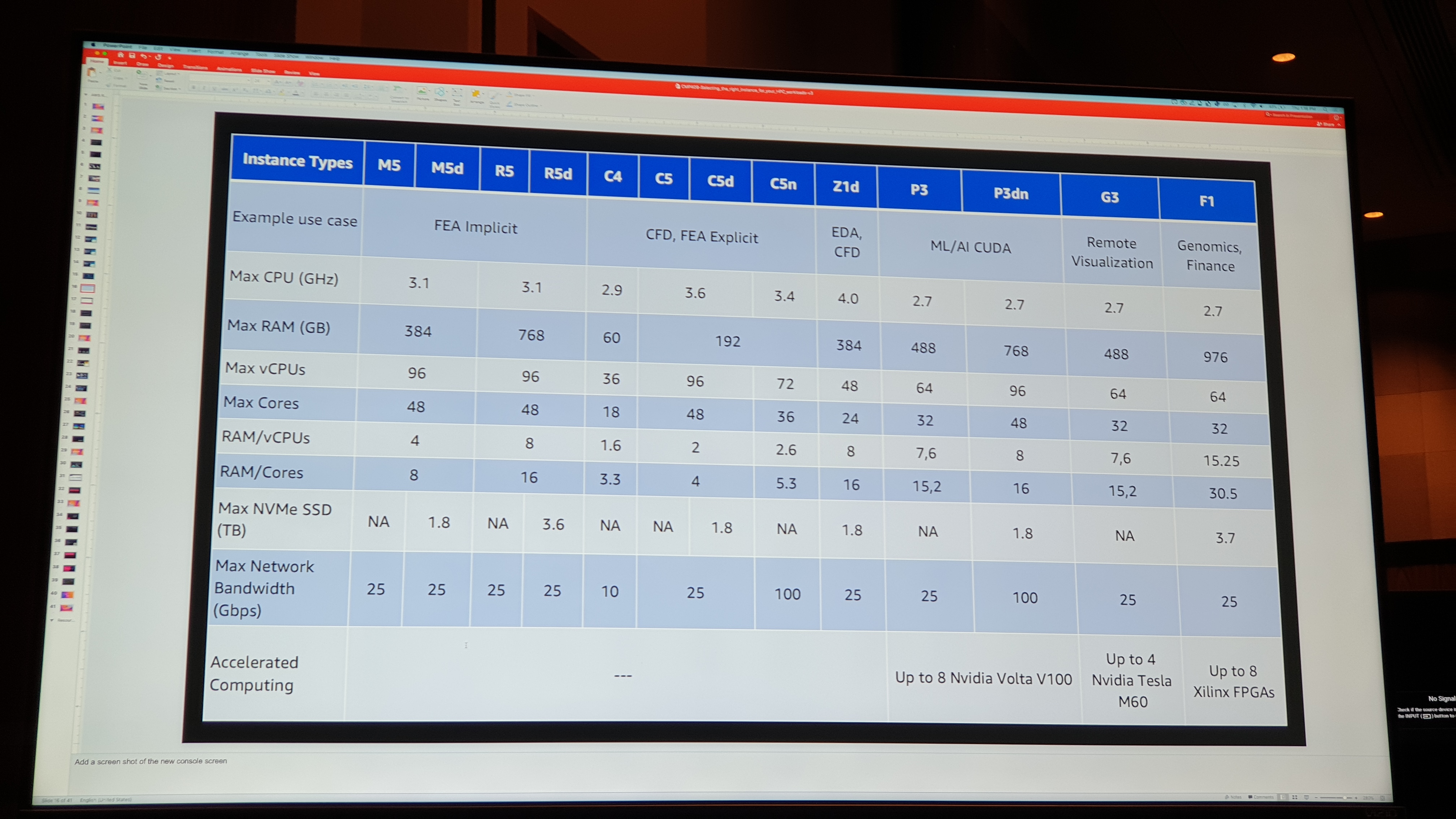
If your workload needs high performance disk performance in-and-out from the server the default AWS recommended choice would be to use Amazon FSx for Lustre cluster storage solution.
If you decide to use the Elastic file system EFS service, you should first think how much you need performance rather than what size you need. The design of EFS promise 200 MBps performance per each 1 TB of data. So, you should rather decide the needed performance so your application will have enough IO bandwidth in-use.
The newest choice is Elastic Fabric Adapter (EFA) which was announced a couple of months ago. More information about EFA can be found from here: https://aws.amazon.com/hpc/efa/
If you don’t have experience which storage would work the best for your workload, it is strongly recommended to test each one and make the decision after that.
Intelligently automating cloud operations – ENT305
This session was a workshop session. In workshop sessions there is multiple tables with same topic and in builder session there is one small table for each topic. So, there were more than hundred persons to do same exercise.
At first Mr. Francesco Penta (Principal Cloud Support Engineer, AWS) and Mr. Tipu Qureshi (Principal Engineer, AWS) gave a short overview of services that we are using in this session. I want to mention few of them. AWS Health keeps track of health of different services in your account. For example, it can alarm if your ACM certificate is not able to renew automatically (e.g. missing DNS records) or VPN tunnel is down.

The other service was AWS Auto Scaling predictive scaling. It is important thing if you want to avoid bigger under-provisioning. When just using e.g. CPU metric from last 5 minutes you are already late, bad. Also, if your horizontal scaling needs awhile to have new nodes in service, then the predictive scaling helps you to get more stable performance.
The workshop can be found here: https://intelligent-cloud-operations.workshop.aws/
I’m familiar with the tooling so I could have yelled Bingo as one of the first persons to finish. I was happy to finish early and go to hotel for short break before the Solita’s customer event and the re:Play. The re:Play starts at 8pm in Las Vegas Festival Grounds with music, food, drinks and more than 30 000 eye pairs.

Would you like to hear more what happens in re:Invent 2019? Sign up to our team’s Whatsapp group to chat with them and register to What happens in Vegas won’t stay in Vegas webinar to hear a whole sum-up after the event.
