As an IT person, I dare say that today we use the cloud without even thinking about it. All kinds of data repositories, social networks, streaming services, media portals – they work thanks to cloud solutions. The cloud now plays an important role in how people interact with technology.
Cloud service providers are inventing more and more features and functionalities, bringing them to the IT market. Such innovative technologies offer even more opportunities for organisations to run a business. For example, AWS, one of the largest providers of public cloud services, announces over 100 product or service updates each year.
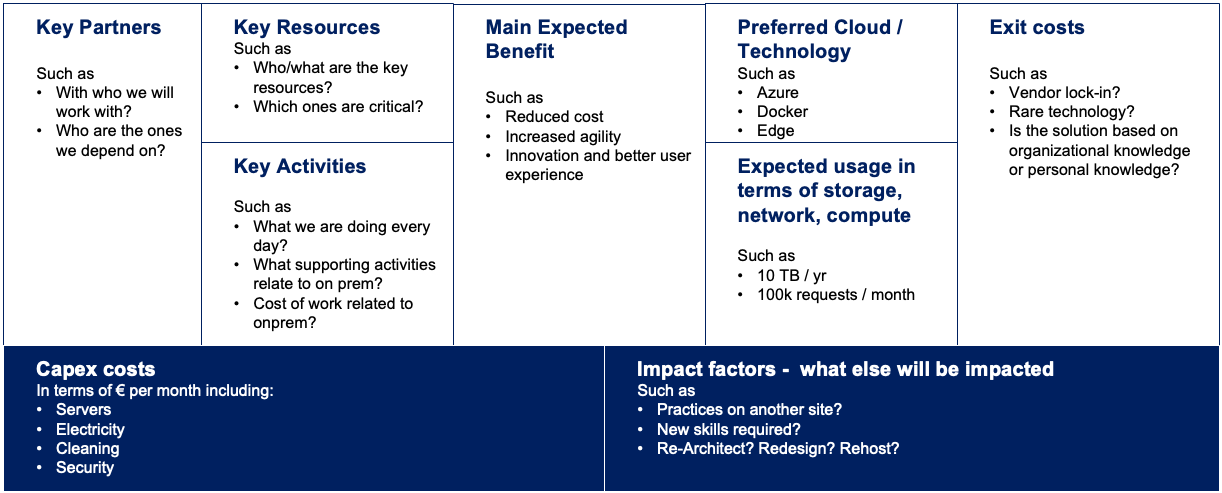
Cloud services
Cloud technologies are of interest to customers due to their economy, flexibility, performance and reliability.
For IT people, one of the most exciting aspects of using cloud services is the speed at which the cloud provides access to a resource or service. A few clicks at a cloud provider’s portal – and you have a server with a multi-core processor and large storage capacity at your disposal. Or a few commands on the service provider’s command line tool – and you have a powerful database ready to use.
Cloud deployment models
In terms of the cloud deployment model, we can identify three main models:
• A public cloud – The service provider has publicly available cloud applications, machines, databases, storage, and other resources. All this wealth runs on the IT infrastructure of the public cloud service provider, who manages it. The best-known players in the public cloud business are AWS, Microsoft Azure and Google Cloud.
In my opinion, one of the most pleasant features of a public cloud is its flexibility. We often refer to it as elasticity. An organisation can embark on its public cloud journey with low resources and low start costs, according to current requirements.
Major public cloud players offer services globally. We can easily launch cloud resources in a geographical manner which best fits our customer market reach.
For example, in a globally deployed public cloud environment, an organization can serve its South American customers from a South American data centre. A data centre located in one of the European countries would serve European customers. This greatly improves the latency and customer satisfaction.
There is no need to invest heavily in hardware, licensing, etc. – organisation spends money over time and only on the resources actually used.
• A private cloud – This is an infrastructure for a single organisation, managed by the organisation itself or by a service provider. The infrastructure can be located in the company’s data centre or elsewhere.
The definition of a private cloud usually includes the IT infrastructure of the organisation’s own data centre. Most of these state-of-the-art on-premise solutions are built using virtualisation software. They offer the flexibility and management capabilities of a cloud.
Here, however, we should keep in mind that the capacity of a data centre is not unlimited. At the same time, the private cloud allows an organisation to implement its own standards for data security. It also allows to follow regulations where applicable. Also, to store data in a suitable geographical area in its data centre, to achieve an ultra low latency, for example.
As usual, everything good comes with trade-offs. Think how complex activity it might be to expand the private cloud into a new region, or even a new continent. Hardware, connectivity, staffing, etc – organisation needs to take care of all this in a new operating area.
• A hybrid cloud – an organisation uses both its data centre IT infrastructure (or its own private cloud) and a public cloud service. Private cloud and public cloud infrastructures are separate but interconnected.
Using this combination, an organisation can store sensitive customer data in an on-premise application according to regulation in a private cloud. At the same time, it can integrate this data with corporate business analytics software that runs in a public cloud. The hybrid cloud allows us to use the strengths of both cloud deployment models.
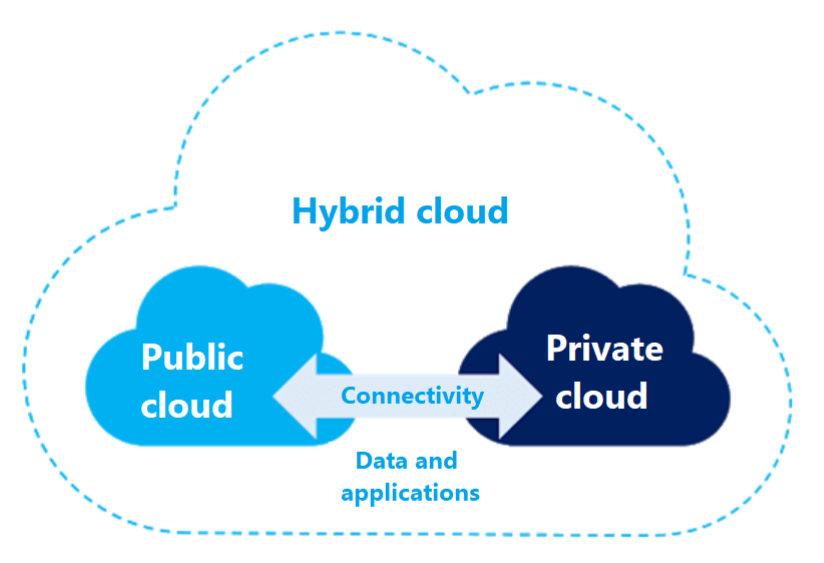
When is a hybrid cloud useful?
Before we dive into the talk about hybrid cloud, I’d like to stress that we at Solita are devoted advocates of cloud-first strategy, referring to public cloud. At the same time, cloud-first does not mean cloud-only, and we recognize that there might be use-cases when running a hybrid model is justified, be it regulation reasons or very low latency requirements.
Let’s look at some examples of when and how a hybrid cloud model can benefit an organisation.
Extra power from the cloud
Suppose that the company has not yet made its migration to public cloud. Reasons can be lack of resources or cloud competence. It is running its private cloud in a colocation data centre. The private cloud is operating at a satisfactional level while the load and resource demand remains stable.
However, the company’s private cloud lacks extra computing resources to handle future events of demand growth. But an increased load on the IT systems is expected due to an upcoming temporary marketing campaign. As a result of the campaign, the number of visitors to the organisation’s public systems will increase significantly. How to address this concern?
The traditional on-premise way used to be getting extra resources in the form of additional hardware. It means new servers, larger storage arrays, more powerful network devices, and so on. This causes additional capital investment, but it is also important that this addition of resources may not be fast.
The organisation must deliver, install, configure the equipment – and these jobs cannot always be automated to save time. After the load on the IT systems has decreased with the end of the marketing campaign, the situation may arise that the acquired additional computing power is not used any more.
But given the capabilities of the cloud, a better solution is to get additional resources from the public cloud. Public cloud allows to do this flexibly and on-demand, as much as the situation requires. The company spends and pays for resources only as it needs them, without large monetary commitments. Let the cloud adoption start 😊
The organisation can access additional resources from the public cloud in hours or even minutes. We can order these programmatically, and in automated fashion in advance, according to the time of the marketing campaign.
When the time comes and there are many more visitors, the company will still keep the availability of its IT systems. They will continue to operate at the required level with the help of additional resources. This method of use is known as cloud bursting, i.e. resources “flow over” to another cloud environment.
This is the moment when a cloud journey begins for the organization. It is an extremely important point of time when the organization must carefully evaluate its cloud competence. It needs to consider possible pitfalls on the road to cloud adoption.
For an organisation, it is often effective to find a good partner to assist with cloud migration. The partner with verified cloud competence will help to get onto cloud adoption rails and go further with cloud migration. My colleagues at Solita have written a great blog post about cloud migration and how to do it right.
High availability and recovery
Implementing high availability in your data centre and/or private cloud can be expensive. As a rule, high availability means that everything must be duplicated – machines, disk arrays, network equipment, power supply, etc. This can also mean double costs.
An additional requirement can be to ensure geo-redundancy of the data and have a copy in another data centre. In such case, the cost of using another data centre will be added.
A good data recovery plan still requires a geographically duplicated recovery site to minimise risk. From the recovery site, a company can quickly get its IT systems back up and running in the event of a major disaster in a major data centre. Is there a good solution to this challenge? Yes, there is.
A hybrid cloud simplifies the implementation of a high availability and recovery plan at a lower cost. As in the previous scenario described above, this is often a good starting point for an organisation’s cloud adoption. Good rule of thumb is to start small, and expand your public cloud presence in controlled steps.
A warm disaster recovery site in the public cloud allows us to use cloud resources sparingly and without capital investment. Data is replicated from the main data centre and stored in the public cloud, but bulky computing resources (servers, databases, etc.) are turned off and do not incur costs.
In an emergency case, when the main data centre is down, the resources on the warm disaster recovery site turn on quickly – either automatically or at the administrator’s command. Because data already exists on the replacement site, such switching is relatively quick and the IT systems have minimal downtime.
Once there is enough cloud competence on board, the organisation will move towards cloud-first strategy. Eventually it would switch its public cloud recovery site to be a primary site, whereas recovery site would move to an on-premise environment.
Hybrid cloud past and present
For several years, the public cloud was advertised as a one-way ticket. Many assumed that organisations would either move all their IT systems to the cloud or continue in their own data centres as they were. It was like there was no other choice, as we could read a few years ago.
As we have seen since then, this paradigm has now changed. It’s remarkable that even the big cloud players AWS and Microsoft Azure don’t rule out the need for a customer to design their IT infrastructure as a hybrid cloud.
Hybrid cloud adoption
Organisations have good reasons why they cannot always move everything to a public cloud. Reasons might include an investment in the existing IT infrastructure, some legal reasons, technical challenges, or something else.
Service providers are now rather favouring the use of a hybrid cloud deployment model. They are trying to make it as convenient as possible for the customer to adopt it. According to the “RightScale 2020 State of the Cloud” report published in 2020, hybrid cloud is actually the dominant cloud strategy for large enterprises:
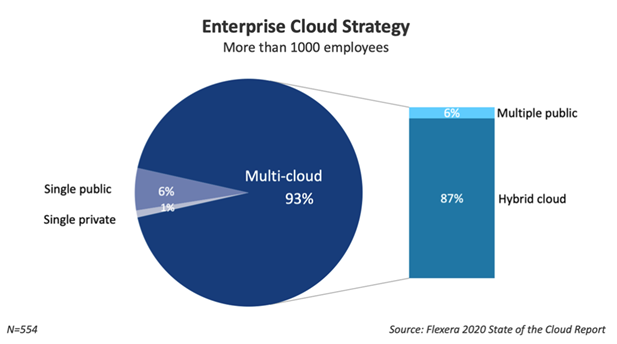
Back in 2019, only 58% of respondents preferred the hybrid cloud as their main strategy. There is a clear signal that the hybrid cloud offers the strengths of several deployment models to organisations. And companies are well aware of the benefits.
Cloud vendors vs Hybrid
How do major service providers operate on the hybrid cloud front? Microsoft Azure came out with Azure Stack – a service that is figuratively speaking a public cloud experience in the organisation’s own data centre.
Developers can write the same cloud native code. It runs in the same way both in a public Azure cloud and in a “small copy” of Azure in the enterprise’s data centre. It gives the real cloud feeling, like a modern extension to a good old house that got small for the family.
Speaking of multi-cloud strategy as mentioned in the above image, Azure Arc product by Microsoft is worth mentioning, as it is designed especially for managing multi-cloud environments and gaining consistency across multiple cloud services.
AWS advertises its hybrid cloud offering portfolio with the message that they understand that not all applications can run in the cloud – some must reside on customers premises, in their machines, or in a specific physical location.
A recent example of hybrid cloud thinking is AWS’s announcement of launching its new service ECS Anywhere. It’s a service that allows customers to run and manage their containers right on their own hardware, in any environment, while taking advantage of all the ECS capabilities that AWS offers in the “real” cloud to operate and monitor the containers. Among other things, it supports “bare” physical hardware and Raspberry Pi. 😊
As we’ve also seen just recently, the next step for Amazon to win hybrid cloud users was the launch of EKS Anywhere – this allows customers using Kubernetes to enjoy the convenience of a managed AWS EKS service while keeping their containers and data in their own environment, on their own data centre’s machines.
As we see, public cloud vendors are trying hard with their hybrid service offerings. It’s possible that after a critical threshold of hybrid services users is reached, it will create the next big wave of cloud adoption in the next few years.
Hybrid cloud trends
The use of hybrid cloud related services mentioned above assumes that there is cloud competence in the organisation. These services integrate tightly with the public cloud. It is important to have skills to manage these correctly in a cloud-native way.
I think we will see a general trend in the near future that the hybrid cloud will remain. Multi-cloud strategy as a whole will grow even bigger. Service providers will assist customers in deploying a hybrid cloud while maintaining a “cloud native” ecosystem. So that the customer has the same approach to developing and operating their IT systems. It will not matter whether the IT system runs in a “real” cloud or on a hybrid model.
The convergence of public, private and hybrid models will evolve, whereas public cloud will continue to lead in the cloud-first festival. Cloud competence and skills around it will become more and more important. The modern infrastructure will not be achievable anymore without leveraging the public cloud.