Greetings dear reader! It’s again the time of the year to travel to London to hear the latest insights from Gartner regarding IT Infrastructure, Operations and Cloud. What makes this journey exiting is that basically all conferences have been virtual or cancelled during the past few years since start of the Covid-19 pandemic. So, it’s time to pack the suitcase and head to London – physically!
The Gartner IT Symposium/Xpo has just been held in Barcelona. Few weeks after IT Symposium Gartner arranges a conference dedicated to IT infrastructure and Operations. This year conference carried the name Gartner IT Infrastructure, Operations & Cloud Strategies and it was arranged during 20th-21st November 2022.

Conference was held just next to O2 arena in InterContinental London – the O2. Place is easy to catch e.g. with an underground.
First registration and then to grab a cup of tea. While having a cup of tea and waiting for the Keynote to start, some autumn view from the window over Thames towards Canary Wharf.

Day 1 Agenda
Agenda that I build for the first day was as follows. Very interesting topics in the sessions, right?
- Keynote: I&O Forward — Leading the Next Phase of Growth
- Avoiding the Top Mistakes in Your Cloud Strategy
- Leadership Vision for 2023: Infrastructure and Operations
- Is Public Cloud Cheaper Than My Data Center?
- How to Implement a Cloud Center of Excellence That Empowers, enables and Educates
In this article, I will summarize some main points per session from my point of view from each session. Let’s start.
Keynote: I&O Forward — Leading the Next Phase of Growth
First day started with Keynote with the topic of “I&O Forward — Leading the Next Phase of Growth”. The main message was that after the pandemic, world has changed and organizations need to rethink how they adapt to new normal to support next phase of growth. The solution was divided into four dimensions.
First, since digital pace of the organizations is increasing, it will set new requirements for collaboration between business and IT. The trend seems to be that technology skills are wanted more and more also outside of IT in the future. This trend will create a new type of a role in business called “Business Technologists”. They will utilize technology and work between business and IT. Digital business is a team work. These teams combining business and IT staff Gartner calls “Fusion teams”.
Second, in order to be fast and innovative, organizations must decrease complexity of platforms. To meet these needs, organizations will accelerate the adoption of intelligent automation and delivery of shared infrastructure platforms. Gartner calls this as a “platform engineering” approach. Yet another buzz word? Maybe – or maybe not. At least the focus of shared platform concept is nicely summarized: Stop focusing on tools – start building engines. As a side note, we have been helping our customer with similar approach using our Solita CloudBlox service offering. Additionally low-code/no-code was mentioned as one of the ways to increase pace and decrease time-to-market in digital development.
Third, for organizations to be competitive and attractive for new talent, they need to put focus on workforce reskilling and dynamic work management.
Finally, when all previous three themes are in place, organizations can establish “innovation engine”. This engine is powered by innovation labs that test and evaluate new technologies and opportunities. Then the best candidates will be further developed.
After the Keynote it was time to head to the first actual session.
Avoiding the Top Mistakes in Your Cloud Strategy
The session went through some key mistakes Gartner had found out organizations are doing when developing their Cloud strategies. The top 10 mistakes were:
- Assuming It’s an IT (Only) Strategy
- Not Having an Exit Strategy
- Combining or Confusing a Cloud Strategy With a Cloud Implementation Plan
- Believing It’s Too Late to Devise a Cloud Strategy
- Equating a Cloud Strategy With “We’re Moving Everything to the Cloud”
- Saying “Our Cloud Strategy Is Our Data Center Strategy” or “It’s All in or Nothing”
- Believing That an Executive Mandate Is a Strategy
- Believing That Being a Shop Means That Is the Cloud Strategy
- Outsourcing Development of Your Cloud Strategy
- Saying “Our Strategy Is Cloud First” Is The Entire Cloud Strategy
I have witnessed same kind of “mistakes” organizations easily fall-into. Therefore, we have developed Business Driven Cloud Strategy, to ensure Cloud strategies are developed business needs in mind. You can check e.g this Crash Course on Business driven cloud adoption for a reference.
Leadership Vision for 2023: Infrastructure and Operations
Next session discussed what IT Infrastructure and Operations leaders are facing in 2023 and beoynd. In summary, session provided answers to the following questions:
- Top challenges facing Infrastructure and Operations leaders?
- Major trends
- What actions leaders need to take?

First, what are the top challenges Infrastructure and Operations leaders are going to face? Insufficient skills is the no. 1 challenge based on Gartner’s survey. Overall, Infrastructure & Operations leaders needs to fix the core capabilities of their units first. Then the next step is to reinvent Infrastructure & Operations, which means e.g. increase customer approach and change in culture and structures.
Second, what are the major trends Infrastructure and Operations leaders need to take into account? First of all, FTE increase was expected in Infrastructure and Operations in the next 12 months. Skill trends will be in understanding business, team collaboration, willingess to embrace change. Not forgetting more technical skills like automation, cloud, monitoring and platform operations skills. Top 3 skills Infrastructure and Operations will be investing: 1) Cloud, 2) Automation and 3) Advanced Analytics.
Third, what are the actions Infrastructure and Operations leaders need to take? Three actions were highlighted: 1) sense, respond and anticipate new business needs. Not an easy task, right? 2) Retain talent by focusing on e.g. in work-life balance. 3) Mature automation in Infrastructure and Operations to unlock innovation in the organization.
Next it was time for a lunch in exhibition area. Plenty of exhibitors were present.

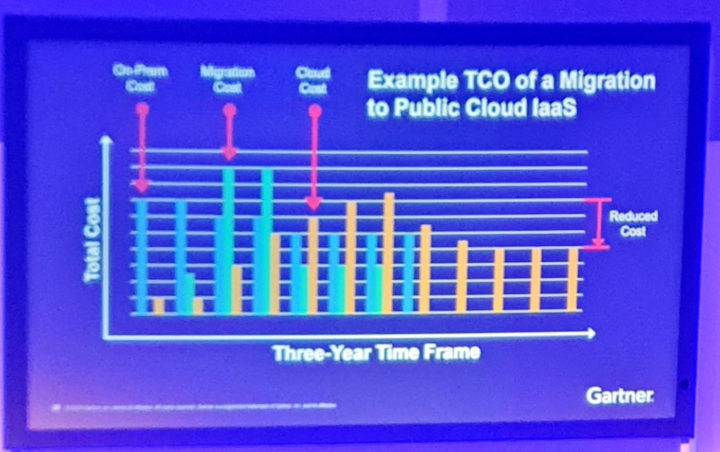
Is Public Cloud Cheaper Than My Data Center?
After the lunch and exhibition area roundtrip, it was time to get back to the sessions. Have you heard debates wheter cloud is cheaper than data center? Yes, I thought so. So, next let’s take a look what I learned from this session.
Comparing cloud and on-premises/data center is not that straightforward task. There are many aspects you can neglect to get cloud or on-premises look more attractive. Instead, focus should in benefits, not only in costs. However, to calculate TCO one needs to calculate it e.g. for a five year period to capture all qualitative benefits and ROI figures. The final conclusion was that cloud brings cost savings compared to on-premises but it takes time, effort and skills to realize them. Therefore, a partner like Solita who manages digital business scene from strategy and design to creating digital services and managing and operating them, can help you succeed in your cloud journey!
Next it was a time for the the final session of the day.
How to Implement a Cloud Center of Excellence That Empowers, Enables and Educates
Last but not least, interesting topic about Cloud Center of Excellence (CCOE) and its latest trends. As a side note, we have run CCOEs together with our customers for years. We also included CCOE as a module into our Solita CloudBlox services to support our customers to succeed in their cloud adoption journeys. So, it’s interesting to see if something new can be adopted based on the session.
Cloud Center of Excellence (CCOE) is at the heart of Cloud Operating model, meaning that it plays a central role between steering and daily operations. I think the illustration of CCOE was now much more understandable in the organization context than previously. It highlighted CCOE key role as a enabler in “Cloud Enterprise Architecture” module. CCOE will co-operate with different councils, cloud community of practise, admin and support and cloud implementation side.
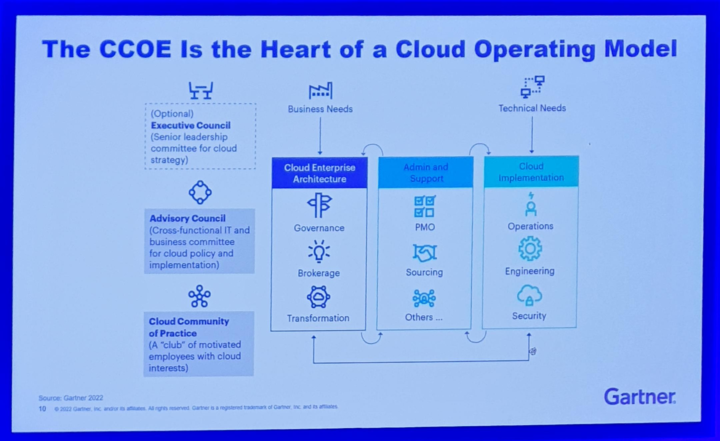
It was also highlighted that CCOE is a temporary function in organization. The main driver for CCOE is to empower and enable the rest of the organization by spreading the cloud knowhow. Once organization is mature enough, a dedicated CCOE can be phased out and be absorbed to Enterprise Archictecture (EA) function or other architecture functions. How long is then temporary? I haven’t yet seen phased out CCOEs but I would assume it’s somewhere between 5-10 years. It depends heavily on how organization is able to adopt cloud knowhow widely.
Final words
So, that was the first day. Full of interesting topics, lots of information, and great speakers! To put it into a nutshell, let my briefly summarize the output from the sessions:
Business units are more and more increasing their technology understanding as “technology users” that are able to utilize tech already themselves.
IT units need to increase collaboration with business and increase their understanding of the business.
Organizations have insufficient skills currently while they also need to increase the amount of workforce who will focus on the utilization of the technology. This sets new demands for recruiting talent and keeping them inhouse.
There is a big opportunity for organizations to modernize their business with public clouds. However, to be successful it requires a lot of skills and competence accross the organization. Therefore partnering with trusted technology, strategy and design provider will bring advantage to the cloud adoption journey.
Finally it’s time to grab some drinks and food in the networking dinner with other conference peers. Then time for a little rest and preparing for the day 2. Thanks for reading, I hope you enjoyed!