

Kicking the tires of AWS Textract
AWS has multiple services in AI/ML field. These include, for example, Amazon Comprehend for text analysis, Amazon Forecast for predicting future from set of data and Amazon Rekognition to extract information from pictures. Amazon Textract is a new service in this field and it was just announced to be generally available. Textract is a service which does Optical Character Recognition (OCR) from multiple file formats and stores output in a more usable format in JSON.
At the moment of release the AWS Textract can detect Latin-script characters from standard English alphabet and ASCII symbols. It can use PNG, JPEG and PDF as input files. I would say that there are enough input formats but would have wanted to see more languages available. Of course Finnish is not something that I assume to see anytime soon or at all. Textract is now available in three regions in US and Ireland in Europe.
Analyse test
Textract allows one to easily test what kind of results they can get with it. One can open Textract service and first see a sample document created by AWS. This helps to get started and get some kind of idea how to use it. Documents can be uploaded directly from the console and it automatically creates a S3 bucket to store them.
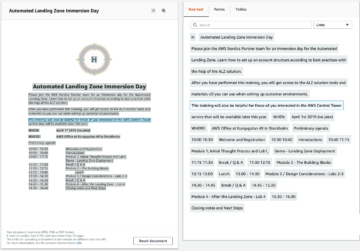
I did tests with multiple files and file formats to see how it performs but used one PDF document as an example for this post. The PDF I used was AWS Landing Zone immersion day information sheet because it was handily available and had text, table and image in it. On the left in the picture, we can see again the areas where Textract has identified content and on the right is the extraction. From this kind of clear and simple document it seems to have picked up everything easily. It took around 10 seconds for this document to be analysed.
I would say that Textract handled all the files I gave it without too much problem. The view of the file and places where it finds text does not always align even though text output is correct. This happened for example with my CV where the visual representation was off on many places.

Results
Outputs can also be downloaded directly from the console in a zip file and it will provide these four files.
- apiResponse.json
- tables.csv
- keyValues.csv
- rawText.txt
Tables.csv, keyValues.csv and rawText.txt are all quite clear. Tables holds all the tables and fields Textract found from the document and keyValues.csv holds form data. This is the table that was found in the document. It has been correctly read and put in table. Interestingly, it has also added empty columns for the long empty spaces between texts.

Rawdata.csv contains extracted text from document in a raw format. It has all the text in non edited format, all the words just after each other.
H Automated Landing Zone Immersion Day Please join the AWS Nordics Partner team for an immersion day for the Automated Landing Zone. Learn how to set up an account structure according to best practices with the help of the ALZ solution. After you have performed this training, you will get access to the ALZ solution tools and materials sO you can use when setting up customer environments. This training will also be helpful for those of you interested in the AWS Control Tower service that will be available later this year. WHEN: April 1st 2019 (no joke) WHERE: AWS Office at Kungsgatan 49 in Stockholm Preliminary agenda 10:00 10:30 Welcome and Registration 10:30 10:40………
Textract also gives a full output of the process. This information is in JSON format and contains all the information about the findings. There is detailed information what was found and in where. It also gives a confidence percentage of the finding. This is a very large JSON document even with a small PDF, almost as big file as the original PDF.
{ "BlockType": "WORD", "Confidence": 99.962646484375, "Text": "account", "Geometry": { "BoundingBox": { "Width": 0.0724315419793129, "Height": 0.012798813171684742, "Left": 0.448628693819046, "Top": 0.37925970554351807 }, "Polygon": [ { "X": 0.448628693819046, "Y": 0.37925970554351807 }, { "X": 0.5210602283477783, "Y": 0.37925970554351807 }, { "X": 0.5210602283477783, "Y": 0.39205852150917053 }, { "X": 0.448628693819046, "Y": 0.39205852150917053 } ] }, "Id": "f1c9bdeb-f76a-44ff-8037-6cb746d5613d", "Page": 1 },
Conclusion
Textract is a needed addition to AWS AI/ML service family and fills the gap in analysis tools. Textract says that it will read English from multiple file formats and seems to do that well. All tests with PDFs and pictures were successful. Of course one wouldn’t use this service like this and upload single files manually. Textract has support in AWS cli and both Java and Python SDKs. That makes it possible to have, for example, automatic triggers in S3 bucket when new files are uploaded which launches Textract to do it’s thing. Overall a nice service which will probably be a very useful one for text analysis use cases.
